개요
요청이 들어오면 서버는 이를 처리하기 위해 여러 가지 방식을 사용할 수 있다.
그중 하나가 Thread Per Request Model이다.
이 방식은 하나의 웹 요청이 들어올 때마다 하나의 독립적인 스레드를 생성하여 해당 요청을 처리한다.
처리가 끝난 스레드는 그대로 버려지고, 새로운 요청이 들어오면 다시 새로운 스레드가 만들어진다.
Thread Per Request Model의 문제점
겉보기에는 단순해 보이지만, 이 방식에는 치명적인 문제가 있다.
- 스레드 생성 비용
요청마다 스레드를 새로 만드는 과정에서 시간이 소요된다.
따라서 요청 처리 시간이 불필요하게 늘어난다. - 스레드 폭증
요청이 스레드 처리 속도보다 빠르게 들어오면 스레드 수가 급격히 증가한다. - 컨텍스트 스위칭 오버헤드
스레드가 많아질수록 CPU는 스레드를 번갈아 가며 실행해야 한다.
이 과정에서 컨텍스트 스위칭이 자주 발생하고 CPU 리소스가 낭비된다. - 서버 불안정
결국 CPU 오버헤드가 누적되고, 어느 순간 서버가 요청에 응답하지 못하게 된다.
최악의 경우 서버 전체가 응답 불가능 상태에 빠질 수 있다. - 메모리 고갈
스레드마다 고정된 메모리(Stack 등)를 점유하기 때문에, 스레드 수가 증가할수록 메모리가 고갈된다.
이는 시스템 안정성에 직접적인 악영향을 미칠 수 있다.
그래서 이부분을 해결하기 위해 스레드 풀(Thread Pool)이라는 개념이 등장한다.
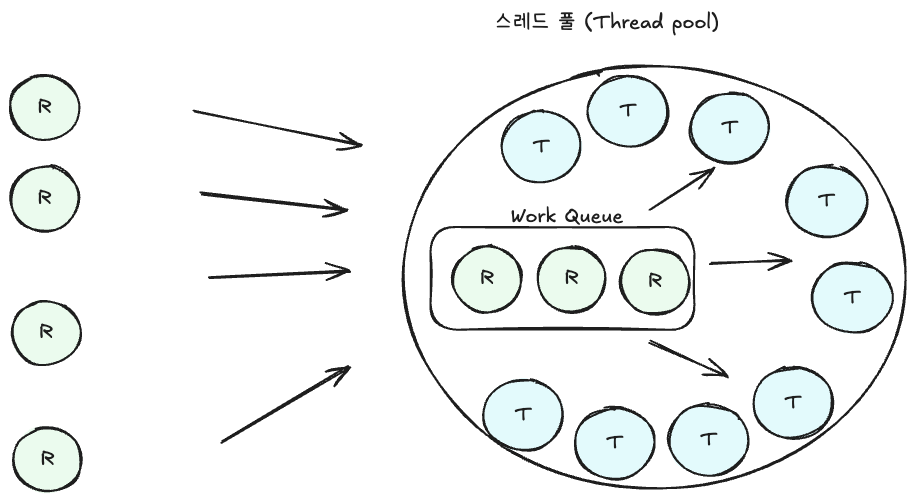
스레드 풀(Thread Pool)
스레드 풀은 미리 정해둔 개수만큼 스레드를 생성해 두고,
들어오는 요청을 내부의 작업 큐(Work Queue)에 담아 관리한다.
큐에 요청이 들어오면, 대기 중이던 스레드가 이를 가져와 실행한다.
즉, 요청마다 새로운 스레드를 생성하지 않고, 이미 준비된 스레드를 재사용하는 방식이다.
스레드 풀의 장점
- 스레드 생성 비용 감소
매 요청마다 스레드를 생성하지 않고, 재사용하기 때문에 응답 속도가 빨라진다. - 스레드 개수 제한
풀의 크기를 제한할 수 있어, 스레드 폭증으로 인한 컨텍스트 스위칭 오버헤드와 메모리 고갈 문제를 예방한다. - 안정적인 자원 관리
요청이 몰려도 일정 수준에서 큐에 쌓아 두고, 준비된 스레드가 처리하기 때문에 시스템이 한 번에 무너지지 않는다.
동작 방식 (간단한 흐름)
- 요청이 들어온다.
- 요청은 작업 큐(Queue)에 쌓인다.
- 3. 스레드 풀의 스레드 중 idle 상태(대기 중)인 스레드가 큐에서 요청을 가져와 실행한다.
- 4. 요청 처리가 끝난 스레드는 다시 풀로 반환되어 재사용된다.
Thread Pool 사례
- 웹 서버: 클라이언트 요청이 많을 때, 각 요청을 스레드 풀에서 효율적으로 처리.
- 데이터베이스 연결 처리: DB 커넥션 풀과 결합해 안정적이고 빠른 질의 처리.
- 멀티코어 활용: CPU 코어 수에 맞게 스레드 풀 크기를 조정해 자원을 최적 활용.
- 대규모 파일 처리: 큰 작업을 작은 단위(Task)로 쪼개어 동시에 실행.
Thread Pool 사용팁
스레드 풀의 크기를 어떻게 정하느냐에 따라 성능이 크게 달라진다.
- CPU Bound Task(연산 위주 작업)
CPU 코어 개수와 비슷하거나, 조금 더 많은 정도가 적절하다.
(예: 8코어 CPU라면 8~10개 정도) - I/O Bound Task (네트워크, DB, 파일 입출력 등)
대기 시간이 많기 때문에 CPU 코어 개수보다 더 많은 스레드가 필요하다.
보통 코어 개수의 1.5배 ~ 2배 이상을 두지만, 시스템 환경에 따라 경험적으로 최적 값을 찾아야 한다.
하지만 스레드 풀에서 실행될 task의 제한이 없다면, 스레드 풀의 큐 사이즈가 제한이 있는지 꼭 확인하는게 좋다.
큐 사이즈 주의
스레드 풀은 내부적으로 작업 큐(Work Queue)를 사용한다.
만약 큐의 크기를 제한하지 않고 무한정으로 두면 어떤 문제가 생길까?
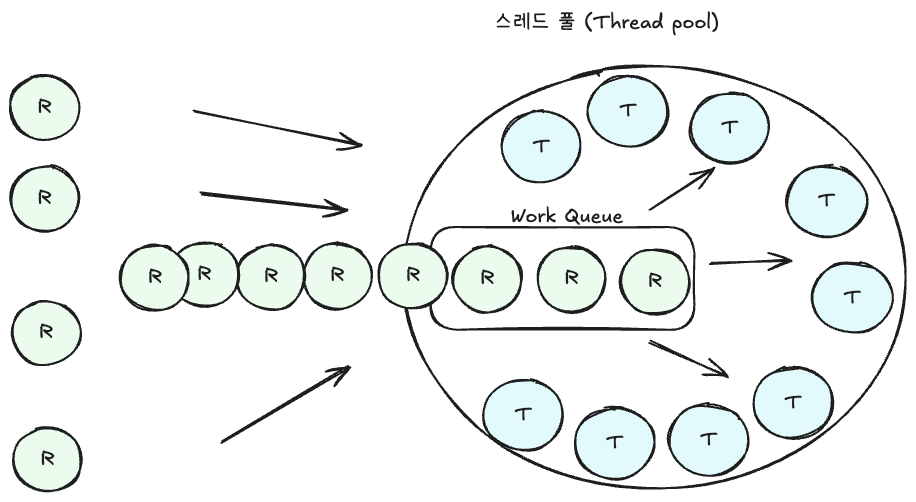
- 요청은 일단 큐에 계속 쌓인다.
- 하지만 처리할 수 있는 스레드가 없기 때문에, 대기 요청은 계속 늘어난다.
- 결국 메모리 고갈을 일으킬 수 있으며, 이는 서버 장애로 이어질 수 있다.
따라서 스레드 풀의 크기뿐만 아니라, 큐의 크기(Queue Capacity)도 반드시 함께 고려해야 한다.
자바에서는 Executors라는 클래스가 있다. Static 메서드로 다양한 형태의 스레드 풀을 제공하고있다.
ExecutorService threadPool = Executors.newFixedThreadPool(10);
executorService.submit(task1);
executorService.submit(task2);
위 코드를 실행하면 스레드 10개로 고정된 스레드 풀이 만들어지고,
submit() 메서드를 통해 작업을 큐에 넣어 실행할 수 있다.
Executors.newFixedThreadPool의 내부

newFixedThreadPool 메서드 내부를 살펴보면,
스레드 풀의 작업 큐로 LinkedBlockingQueue를 사용한다는 것을 알 수 있다.
LinkedBlockingQueue의 생성자를 보면 아래와 같은 코드가 있다:


이 코드를 확인할수 있다. 이 capacity가 말하는값이 queue의 사이즈를 의미하는데, 지금 보면 queue사이즈로 Integer.MAX_VALUE를 받는데 Integer.MAX_VALUE의 값은 자바에서 20억이 넘는 값인데 이말은 거의 제한이 없다는 말과 같다.
즉, 별도의 크기를 지정하지 않으면 기본 용량(capacity)은 Integer.MAX_VALUE이다.
그렇기 때문에 Executors.newFixedThreadPool 를 통해 스레드풀을 만들때 queue의 값이 제한되지 않고 생성된다는걸 알고있어야한다.
문제점: 사실상 무제한 큐
Integer.MAX_VALUE는 자바에서 약 21억에 해당하는 값이다.
즉, 사실상 큐의 크기에 제한이 없는 것과 마찬가지다.
이는 무슨 의미일까?
- 스레드 풀 크기를 제한해도, 요청(task)은 계속 큐에 쌓인다.
- 큐에 무한정 쌓이면 메모리 고갈이 발생할 수 있다.
- 결국 서버가 뻗어버리는 잠재적 위험 요소가 된다.
정리
- Executors.newFixedThreadPool()은 간단하게 스레드 풀을 만들 수 있는 방법이다.
- 하지만 내부적으로 사용하는 큐(LinkedBlockingQueue)가 기본 무제한이라는 점을 반드시 알고 있어야 한다.
- 따라서 실무에서는 ThreadPoolExecutor를 직접 생성하여 corePoolSize, maximumPoolSize, queueSize, 거부 정책(RejectedExecutionHandler) 등을 명시적으로 설정하는 것이 안전하다.
'CS > 운영체제' 카테고리의 다른 글
| Monitor(모니터) 개념과 자바 예제 (0) | 2025.09.03 |
|---|---|
| 스핀락(spinlock) 뮤텍스(mutex) 세마포(semaphore) 각각 특징과 차이 (0) | 2025.09.02 |
| 스레드 (Thread)의 종류 (1) | 2025.08.30 |
| 프로세스와 쓰레드 개념 정리 (1) | 2025.07.17 |
